Нужна помошь знатоков по векторным операциям
- Автор темы Andots
- Дата создания
Вот что интересно. И ведь не написано про это.
рез.
62.000000 9.000000 1.000000 1.000000 2.000000 5.000000 3.000000 -4.000000
Он разворачивает задом наперед. Потому у меня и ошибка была.
Код:
#include <immintrin.h>
#include <stdio.h>
#include <iostream>
#include <conio.h>
int main() {
/* Initialize the two argument vectors */
__m256 evens = _mm256_set_ps(2.0, 4.0, 6.0, 9.0, 10.0, 12.0,22.0, 77.0);
__m256 odds = _mm256_set_ps(6.0, 1.0, 1.0, 7.0, 9.0, 11.0, 13.0, 15.0);
/* Compute the difference between the two vectors */
__m256 result = _mm256_sub_ps(evens, odds);
/* Display the elements of the result vector */
float* f = (float*)&result;
printf("%f %f %f %f %f %f %f %f\n",
f[0], f[1], f[2], f[3], f[4], f[5], f[6], f[7]);
system("pause");
return 0;
}62.000000 9.000000 1.000000 1.000000 2.000000 5.000000 3.000000 -4.000000
Он разворачивает задом наперед. Потому у меня и ошибка была.
Так это стандарт x86, сперва младшии байты суются потом старшии. Эхо аcсемблера, интрисинки они как помесь асма и ся.
"
---Размер массивов-- : 4097152
Стандартный алгоритм без многоядерности 0.087сек;
Стандартный алгоритм с многоядерностью 0.027сек;
SSE с Многоядерностью 0.025сек;
AVX Многояд 0.019сек;
"
Ускорилось конечно не сильно, но суть в том что ускорилось. Одно не пойму
к примеру.
на 1м ядре 0.064сек стандарт, 0.078сек - AVX. В чем прикол, не понимаю, выравнивание сделал. Почему на 4х ядрах быстрее, а одном медленнее, логики нет как то.
Почему на 4х ядрах быстрее, а одном медленнее, логики нет как то.
По старому вопросу почему не работает __asm, потому что выкинули его из x64. Компиль в 32, на скорость это не влияет, зато инлайн асм можно юзать.
Из-за кэширование подозреваю. Перед каждым тестом делай холостой прогон без замера, замеры со второго бери. Или местами поменяй тесты, сперва 4е ядра, потом один.
По старому вопросу почему не работает __asm, потому что выкинули его из x64. Компиль в 32, на скорость это не влияет, зато инлайн асм можно юзать.
По старому вопросу почему не работает __asm, потому что выкинули его из x64. Компиль в 32, на скорость это не влияет, зато инлайн асм можно юзать.
Вот у меня к тебе 1 маленький вопрос, извини что напрягаю и отвелекаю, но вопрос простой.
Есть массив с весами деформера допустм mArr Weight , забирается при подлключении weight map пока plug не dirty больше не трогается.
Далее забирается массив с индексами всех верктексов points.
И абсолютно во всех деформерах которые я видел (из девкита, из других источников) далее начинается полная глупость на мой взгляд.
for ( i = 0; i < points.length(); i++)
get points
...
...
F = бла бла бла * на Weight
set points
1. накой хрен если в данном индексе вес равен 0 считать формулы и умножать ее на 0
Не лучше ли написать if Weight !=0 { } и тупо пропустить блок формул.
2. Либо сразу создать массив pointsNew который забьется при инициализации по условию if Weight !=0 и будет содержать индексы вертексов у которых вес не равен нулю. И дабы вообще исключить ненужные итерации сделать так
for ( i = 0; i < pointsNew.length(); i++)
jn= pointsNew i];
get points[jn]
F = бла бла бла * на Weight[jn]
set points[jn];
Это я чего то просто не понимаю, или народ не додумался?? Твое мнение, что быстрее будет работать?
Если формула простая, то может и быстрее быть, чем при if, ветвления ступорят конвеер, хотя скорее это задел под векторизацию цикла, если нет ветвлений в цикле - компилятор намного эффективней сделает векторизацию, если он это умеет.
А может просто пофигизм.
А может действуют по программерской библейской истине - "Преждевременная оптимизация - корень всех бед", вот ты нарушаешь эту заповедь кстати. Это болезнь - преждевременная оптимизация, я тоже болею этим, но мне нравится)))
Потом примеры в СДК они как учебные, поэтому без оптимизации, оптимизация запутает код.
Второй способ, в принципе может и хорошо будет, конкретно на задаче нужно проверять.
Тут практически проще проверить, варианты простые и легко код можно поменять.
А может просто пофигизм.
А может действуют по программерской библейской истине - "Преждевременная оптимизация - корень всех бед", вот ты нарушаешь эту заповедь кстати. Это болезнь - преждевременная оптимизация, я тоже болею этим, но мне нравится)))
Потом примеры в СДК они как учебные, поэтому без оптимизации, оптимизация запутает код.
Второй способ, в принципе может и хорошо будет, конкретно на задаче нужно проверять.
Тут практически проще проверить, варианты простые и легко код можно поменять.
Последнее редактирование:
Если формула простая, то может и быстрее быть, чем при if, ветвления ступорят конвеер, хотя скорее это задел под векторизацию цикла, если нет ветвлений в цикле - компилятор намного эффективней сделает векторизацию, если он это умеет.
5 баллов.
Некоторые еще и используют встроенный майский итератор
for ( ; !itGeo.isDone(); itGeo.next() )
{
point = itGeo.position(); }
Который хрен распаралелишь по простому, поскольку !itGeo.isDone величина не константная, да в куду какую нить не запихаешь.
Да любой майский деформер возьми, молотит всю геометрию и плевать ему на то какой ты ему вес нарисовал. Maya muсkle вот тоже хороший пример, достаточно подцепить 1 мускулу к скину и тормоза обеспечены( если меш достаточно весомый), ему плевать что она двигает всего 50 - 100 вертексов, он будет молотить всю геометрию и умножать на вес этой мускулы.
Видимо эффект заржавения извилин, делаем так как нас учили и как мы видели у других))))
Да, я нашёл сейчас много кода с for (; !itGeo.isDone(); itGeo.next())
Возьми эти исходники, поставь ифы и проверь практически.
У итератора длину взять itGeo.count()
Возьми эти исходники, поставь ифы и проверь практически.
У итератора длину взять itGeo.count()
Да, я нашёл сейчас много кода с for (; !itGeo.isDone(); itGeo.next())
Возьми эти исходники, поставь ифы и проверь практически.
У итератора длину взять itGeo.count()
Возьми эти исходники, поставь ифы и проверь практически.
У итератора длину взять itGeo.count()
Сделаю строго по канонам жанра, как ты там говорил.
"Преждевременная оптимизация - корень всех бед"
На самом деле есть смысл в этой фразе
")
У итератора длину взять itGeo.count()
Тупо #pragma omp ... не поставишь, придется майскими пулами и прочей ерундой пользоваться.
А смысл, один фиг целая история для распараллеливания
Тупо #pragma omp ... не поставишь, придется майскими пулами и прочей ерундой пользоваться.
Тупо #pragma omp ... не поставишь, придется майскими пулами и прочей ерундой пользоваться.
например по той ссылке код
Код:
46 for (; !itGeo.isDone(); itGeo.next())
47 {
48 point = itGeo.position();
49 w = weightValue(data, geomIndex, itGeo.index());
50
51 point += (blendPoints[itGeo.index()] - point) * blendWeight * env * w;
52
53 itGeo.setPosition(point);
54 }
Преждевременная оптимизация - корень всех бед"
На самом деле есть смысл в этой фразе
На самом деле есть смысл в этой фразе
Ну не знаю, автоматом мне думаетюся он не разложит, придется вручную плясать. Мне кажется он вообще не поймет этот цикл. Хотя кто его знает как он там работает,, все же наверное лучше использовать стандартные итераторы. Этот только 1 раз массив собрать из индексов.
Итератор можно по идексу брать? не буду сейчас рыться в апи. Саму шапку цикла только переписать.
itGeo.isDone(); itGeo.next() вообще не использовать.
В цикле лазить в итератор по индексу.
В принципи да, но могу сказать что я уже несколько раз попарился с майскими атрибутами и скорей всего не прокатит. Во первых itGeo.count() может не потдержать и скорей всего не потдержит ++!itGeo.isDone. Как ты шаг задашь, второе этот итератор пропускает вертексы исключенные из деформ мембешипа потому если его переписать то в нем пропадает всякий смысл. Т.е он дает не каждый вертекс. И по этой же причине ОМП может его не понять.
Т.е это грубо говоря не итератор а целый класс со своими прибамбасами.
Т.е это грубо говоря не итератор а целый класс со своими прибамбасами.
В принципи да, но могу сказать что я уже несколько раз попарился с майскими атрибутами и скорей всего не прокатит. Во первых itGeo.count() может не потдержать и скорей всего не потдержит ++!itGeo.isDone. Как ты шаг задашь, второе этот итератор пропускает вертексы исключенные из деформ мембешипа потому если его переписать то в нем пропадает всякий смысл. Т.е он дает не каждый вертекс. И по этой же причине ОМП может его не понять.
Т.е это грубо говоря не итератор а целый класс со своими прибамбасами.
Т.е это грубо говоря не итератор а целый класс со своими прибамбасами.
+
Посмотрел, в примерах есть splatDeformer.cpp с циклом omp,
итератор меняется после цикла через iter.setAllPositions(verts);
Код:
MItGeometry iter(outputData, groupId, false);
...
// get all points at once. Faster to query, and also better for
// threading than using iterator
MPointArray verts;
iter.allPositions(verts);
int nPoints = verts.length();
...
#pragma omp parallel for
for(int i=0; i<nPoints; i++) {
...
// default OpenMP scheduling breaks traversal into large
// chunks, so low risk of false sharing here in array write.
verts[i] = meshPoint.getPoint();
}
...
// write values back onto output using fast set method on iterator
iter.setAllPositions(verts);
Последнее редактирование:
Кстати, это плаг с задачей на пересечение сеток и он простой.
А я пропустил его. Хороший примерчик. Но чооорт, он тоже используетMMeshIntersector intersector;
intersector.create(dSurf);
который однопоточный и 100% ни разу не оптимизированный. Я хочу свой интесектор написать, но пока не пойму как это лучше сделать. Да и толковый алгоритм пока не нашел. У меня идея есть сделать возможность рисовать карту коллизий на мешах, дабы исключить из расчета остальные точки, а этот итесектор чекает для 1й точки базового меша все точки на противоположном меше, в итоге 80% вычислительных ресурсов может только один он захавать.
Вообще есть у меня одна идейка, надо ее додумать просто. Я рисуночек набросал. Суть в том что поскольку нам известны нормали мы можем найти 2 виртуальные точки с разных сторон на нормалях от ближайшей точки. Ну и ввести ручной параметр глубина коллизии. Далее логикой просто по разнице расстояний l1,l2,l3 ну или по углам треугольников, там к примеру углы у онования нормали смотреть если <90 то внутри,Можно даже 1 вирт точку убрать верхнюю, думаю реально вычислить находится ли точка коллидера внутри этой глубины.
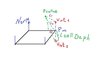
Ну надо еще домозговать эту тему.
Пока навскидку это будет быстрее работать чем стандарт, возможно не так четко и точно. Но зато будет поддаваться ручной настройке и можно будет использовать маски.
Ну в общем я хочу минимизировать присутствие кривых рук разработчиков майки в моем плаге. Максимум get индексы и координаты и set.
Последнее редактирование:
Ты так по гроб будешь свои сетки пересекать, изобретая велосипед.
Вот пишут в газете в апи:
Mesh intersector.
The MMeshIntersector class contains methods for efficiently finding the closest point to a mesh. An octree algorithm is used to find the closest point.
http://download.autodesk.com/us/maya/2009help/api/class_m_mesh_intersector.html
Вот и смотри октодеревья https://ru.wikipedia.org/wiki/Октодерево
ссыли в конце, исходники и теория. Берешь готовое и на ГПУ бросай.
Вот пишут в газете в апи:
Mesh intersector.
The MMeshIntersector class contains methods for efficiently finding the closest point to a mesh. An octree algorithm is used to find the closest point.
http://download.autodesk.com/us/maya/2009help/api/class_m_mesh_intersector.html
Вот и смотри октодеревья https://ru.wikipedia.org/wiki/Октодерево
ссыли в конце, исходники и теория. Берешь готовое и на ГПУ бросай.
Ну если не пытаться изобрести велосипед, то и жить неинтересно.
Это я на потом оставил, тут хоть бы просто стандартом получить то что задумал, тоже целая история. Приходитьтся на целую страницу расшаркиваться чтоб до определенного атрибута добраться. И конечно неудобно что дебажить сразу нельзя, не всегда понятно что ты там на вход подал и что получил, все в голове.
Касаемо интерсекиций как вариант была еще идея рейкаст попробовать, но все это потом.
Ps. ты не вкурсе сколько тактов жрет if (насколько стопорит корвейер)
Что быстрее будет работать
к примеру (формула специально простенькая поскольку на большой понятно что лучше if поставить.
if a >= 0.001 {form = (vecC+vecd+vecV)*a;
else form = 0;
Или тупо считать считать формулу до победного хотя "a" уже 0.000001 и мне нафиг такая погрешность не нужна.
Хотя че я туплю, надо проверить на стенде просто. Ну мало ли может кол-во тактов знаешь, чтоб каждую формулу не проверять потом.
Это я на потом оставил, тут хоть бы просто стандартом получить то что задумал, тоже целая история. Приходитьтся на целую страницу расшаркиваться чтоб до определенного атрибута добраться. И конечно неудобно что дебажить сразу нельзя, не всегда понятно что ты там на вход подал и что получил, все в голове.
Касаемо интерсекиций как вариант была еще идея рейкаст попробовать, но все это потом.
Ps. ты не вкурсе сколько тактов жрет if (насколько стопорит корвейер)
Что быстрее будет работать
к примеру (формула специально простенькая поскольку на большой понятно что лучше if поставить.
if a >= 0.001 {form = (vecC+vecd+vecV)*a;
else form = 0;
Или тупо считать считать формулу до победного хотя "a" уже 0.000001 и мне нафиг такая погрешность не нужна.
Хотя че я туплю, надо проверить на стенде просто. Ну мало ли может кол-во тактов знаешь, чтоб каждую формулу не проверять потом.
Последнее редактирование:
Хм. Чтоб там не говорили что "if" это зло, но даже на простой формуле подобное исключение ускорило цикл в 2 раза
"
float Azr = 0.0001; Resx = Ax + (Cx - Ax)*disx * disx*Azr / (disx * disx);
время 0.025 сек
float Azr = 0.0001;
if (Azr >= 0.001); Resx = Ax + (Cx - Ax)*disx * disx*Azr / (disx * disx);
else
Resx = Ax;
время 0.01 сек
"
float Azr = 0.0001; Resx = Ax + (Cx - Ax)*disx * disx*Azr / (disx * disx);
время 0.025 сек
float Azr = 0.0001;
if (Azr >= 0.001); Resx = Ax + (Cx - Ax)*disx * disx*Azr / (disx * disx);
else
Resx = Ax;
время 0.01 сек
Последнее редактирование:
У if нет фиксированого числа тактов, там может и 1000 быть, ступор конвеера происходит из-за неверного предсказания перехода.
Для майских апишных циклов конечно с иф будет лучше, там вообще число тактов не имеет смысла считать, оно всегда будет немеренным.
Для тяжёлых формул тоже, деление есть в формуле - она уже тянет на тяжёлую.
Иногда задачу можно свести к большому кол-ву элементарных формул, например задачи для обработки изображений, там иф зло.
Да много всяких нюансов, расписывать можно часами.
Для майских апишных циклов конечно с иф будет лучше, там вообще число тактов не имеет смысла считать, оно всегда будет немеренным.
Для тяжёлых формул тоже, деление есть в формуле - она уже тянет на тяжёлую.
Иногда задачу можно свести к большому кол-ву элементарных формул, например задачи для обработки изображений, там иф зло.
Да много всяких нюансов, расписывать можно часами.