Знакомство с NVIDIA CUDA, параллельные вычисления с помощью GPU в CG
В очередной статье о технологиях корпорации NVIDIA, мы поговорим о NVIDIA CUDA - технологии параллельных вычислений с помощью GPU. В основе статьи лежит инетервью с ведущим специалистом по технологиям NVIDIA - Юрием Уральским. Юрий достаточно подробно рассказал о CUDA и перспективах применения этой технологии для увеличения произвоидтельности в различных областях. Однако мы сделали упор на применении CUDA в CG и особенно для визуализации, а так же вычислений сложных эффектов с применением GPU как основного инструмента ускорения вычислений.
На этот раз, вводный ролик к статье будет обладать легким оттенком PR, почему, вы узнаете в конце статьи — в разделе Making Of.
Все смотрели программу MythBusters (Разрушители мифов), и все, знают Джеми и Адама? На прошлом NVIDIA NVISION 08 эти ребята в самой доступной и наглядной форме показали различия между CPU и GPU вычислениям.
Видео-введение
В данном видео-введении автор статьи познакомит Вас с темой статьи.
Введение
В наше время уже ничем не удивить. У нас появились телефоны, которые с легкостью умещающиеся в ладони и управляются всего лишь прикосновениями пальца к дисплею. Совершенно крохотные аудио-плееры, функции которых, между прочим, с легкостью заменяет все тот же телефон. Высокоскоростные каналы связи, с помощью которых без задержек можно обмениваться большими объемами различной информации. Сверхпроизводительные процессоры и тонкие ноутбуки все с теми же производительными процессорами. Но стоит одна большая проблема — обработка информации и данных в установленные сроки. Бывает, что даже самых современных серверных залов с самыми современными процессорами будет недостаточно и очень экономически невыгодно использовать для решений поставленных задач.
Здесь вступает в игру не так давно получившее массовое признание, направление GPGPU — параллельные вычисления на графических процессорах.
В представленном вашему вниманию обзоре-интервью мы продолжим знакомство с технологиями корпорации NVIDIA и поговорим о NVIDIA CUDA. Но мы сделаем упор на применение этого инструмента в нашей с вами области — компьютерной графике (CG). Статья представляет собой интервью с ведущим специалистом по технологиям NVIDIA – Юрием Уральским. Некоторые вопросы дополнены комментарием автора и более детальным разъяснением. Также, имеется видео-версия этого интервью, с дополнительными видео-материалами. В конце статьи даны ссылки на все использованные в статье материалы и программное обеспечение.
Не обойдем стороной и новые технологии, использующие NVIDIA CUDA для самых разных задач. Рассмотрим NVIDIA PhysX с точки зрения его реализации, познакомимся с новыми системами визуализации от mental images – разработчика легендарного mental ray, и многое другое.
Но на самом деле хочется заранее оговориться, что материала настолько много и темы, которые мы здесь затронем, заслуживают отдельного внимания, которое им лучше уделить в отдельных статьях. Поэтому здесь будут рассмотрены все технологии вкратце, по мере появления их на рынке в виде готовых решений.
Итак, приступаем!
Интервью с Юрием Уральским (NVIDIA Corp.)
Когда я этим летом ездил в Москву на CG EVENT 2009, мне довелось посетить Российское представительство корпорации NVIDIA в Москве. Тема посещения, разумеется, была — технология NVIDIA CUDA и применение её в CG. С вопросами и за разъяснениями я обратился к Юрию Уральскому — ведущему специалисту по технологиям NVIDIA.

Ведущий специалист по технологиям NVIDIA – Юрий Уральский.
Интервью представлено в виде диалога с Юрием, как в текстовом, так и в видео варианте.
Первая часть видео-версии интервью с Юрием Уральским.
Dimson3d | Добрый день Юрий, спасибо, что согласились дать интервью для on-line журнала render.ru. Расскажите, пожалуйста, о NVIDIA CUDA, как появилось направление GPGPU и что стало предпосылкой к созданию технологии CUDA?
Стоит начать с вопроса — Что такое CUDA? CUDA — платформа, а не какой-то язык программирования, не какая-то среда программирования, а платформа, которая позволяет использовать мощности графических процессоров (GPU) для вычислений общего назначения. Почему это стало интересно? Примерно в 2003 году сформировалось сообщество энтузиастов, которые стали использовать GPU для запуска произвольного кода. Тогда еще не было CUDA, были стандартные графические API. Но примерно в то время GPU стали достаточно программируемыми. То есть появилось понятие графического шейдера, Open GL и Direct X фактически позволял вам сконфигурировать графический pipeline визуализации. К примеру, расчет цвета пикселя, указать какие текстуры используются и по каким правилам смешиваются, каким образом получается пиксель. Примерно в 2003 году появилась программируемость, разработчики получили возможность написать произвольную программу, которая выполнялась на каждом пикселе и вычисляла, какой ни будь алгоритм. Вместо того, чтобы фиксированным образом конфигурировать графический pipeline, появилась возможность описывать действия, которые производятся над каждой вершиной или пикселем в виде программы. При этом интерфейс GPU оставался сугубо графическим. Т.е. все равно нужно было использовать Direct X или Open GL. Можно так сказать, что графический конвейер остался тем же самым, но мы добавили программируемость в определенные места этого конвейера. Т.е. в конфигурируемом конвейере появилась возможность заменять участки на программы. При этом энтузиасты поняли, что эту возможность можно использовать не только для графики, но и для любых вычислений. Если представить, что мы вычисляем не цвета пикселей, а какие то значения, решаем уравнения. При этом соответственно ваш экран или массив пикселей, который вы считаете, становится выходным массивом данных, а ваша «текстура», которую вы подаете — входным массивом данных. Это то, что называется GPGPU.
Естественно, программирование, таким образом, было сопряжено с большими трудностями, потому что разработчикам нужно было изучать API, понимать, как работает графический ускоритель, и для многих это оставалось недоступным. Если человек исследователь, в какой-то предметной области несвязанной никак с графикой, ему соответственно требовалось время и ресурсы чтобы изучить саму программную модель того же Direct X. Но, тем не менее, люди этим занимались. Почему это было интересно? Потому что для большого класса задач оказалось, что производительность, которую они получают, используя GPU, значительно превосходила CPU.
Примерно в то время мы за этим очень внимательно наблюдали и попытались проанализировать все проблемы, с которыми разработчики сталкивались, и мы решили создать свою программную модель, которая все эти проблемы решала. То есть модель-платформа, которая позволяла запускать произвольный код на GPU. Собственно это идея, которая лежит в основе CUDA. Сама CUDA на рынке появилась в конце 2006 года. С приходом архитектуры G80. Когда появились карты GeForce 8800 — первые наши продукты, которые поддерживали CUDA.
Dimson3d | Архитектура у G80 была существенно переработана?
Совершенно верно, такие нововведения кардинальны и они требовали значительных изменений в самой базовой архитектуре. Все наши чипы до G80 кардинально отличались оттого, что было после G80. Именно в силу того, что мы предоставили возможность запускать произвольный код на GPU связанный не только с графикой.
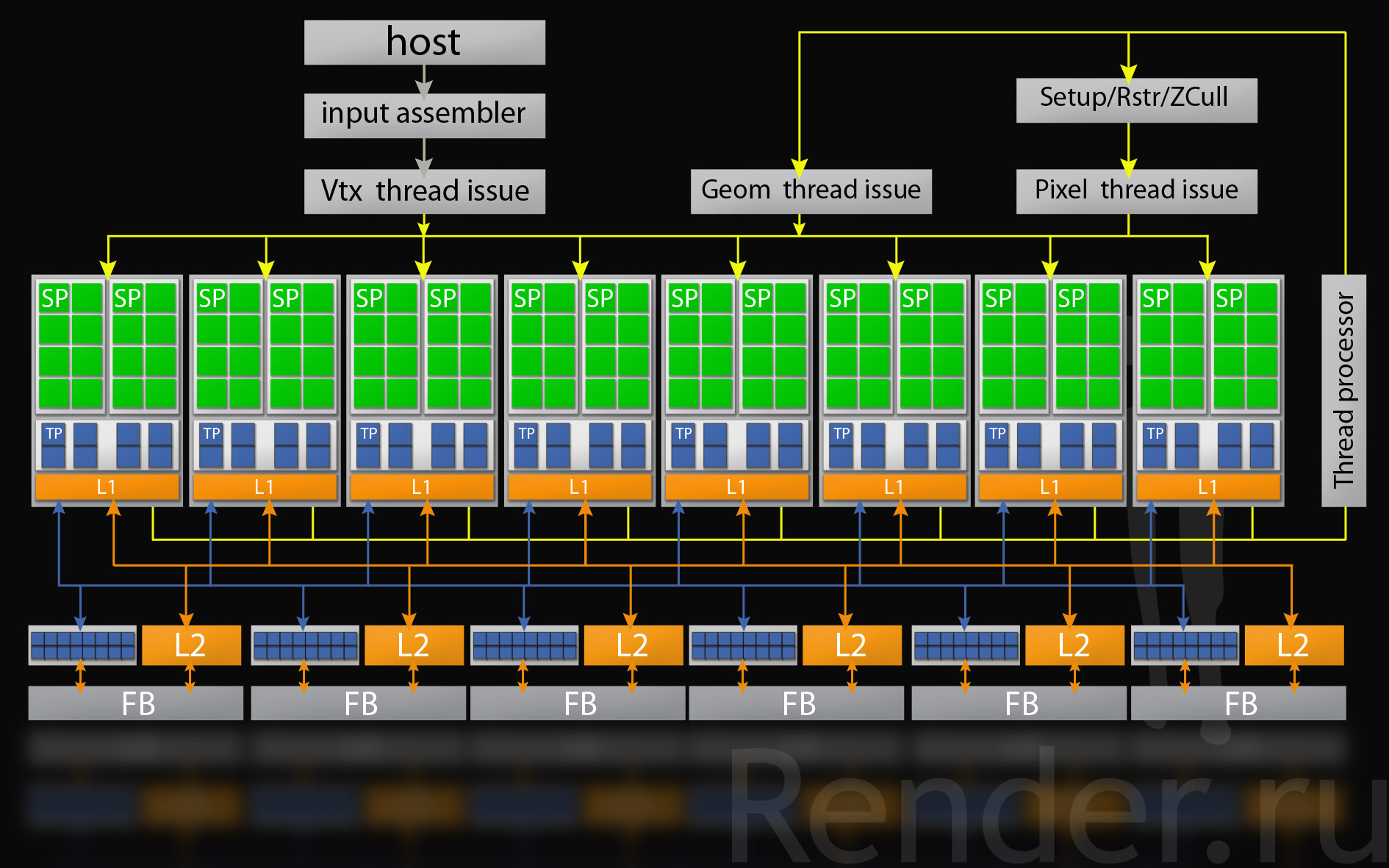
Архитектура чипа G80.
Еще раз подчеркну, что CUDA — не какой то конкретный язык программирования. Люди зачастую ассоциируют с языком C и в принципе изначально мы такие заявления делали — что CUDA - язык программирования. Теперь мы пытаемся от этого уйти, то есть CUDA – именно платформа. Набор средств, которые позволяют вам использовать возможности GPU для вычислений. На данный момент у нас есть компилятор с языка С, но это не значит, что в будущем будет только он. У нас есть планы по поддержке других языков, будет Open CL, DX Compute, все это языки программирования, программные среды поддерживают одну и туже базовую модель вычислений, и туже базовую архитектуру. Вот эта архитектура называется CUDA.
Dimson3d | Скажите, а какие различия существуют, между разработкой для CPU и GPU?
Наверное, в первую очередь, стоит отметить, какие архитектурные отличия существуют между CPU и GPU. Потому что из этого будут следовать отличия программирования. То есть GPU по сути своей — массивно параллельный процессор. Традиционная модель вычислений на CPU подразумевает последовательную модель исполнения. То есть у вас есть программа набор инструкций и эти инструкции вы выполняете одну за другой последовательно. А GPU подходит к проблеме совсем с другой стороны. Мы изначально предполагаем что, в наборе данных задач, которые мы обрабатываем, присутствует очень высокая степень параллелизма. То есть если мы говорим о графике, то совершенно естественно у вас большое количество пикселей на экране, большое количество вершин, треугольников и с этим большим массивом данных вам необходимо провести действия, но которые сходны. Одна последовательность действий, одна программа, которая исполняется сразу в массивно-параллельном режиме. В соответствии со свойством таких систем, мы изначально имели дело с очень массивно-параллельными задачами — коими являются графические задачи. Исходя из этого, архитектура GPU сильно отличается от архитектуры CPU. Мы имеем дело с большим массивом вычислительных модулей. Каждый, из которых работает в какой-то степени независимо, но все они выполняют одну последовательность действий одну программу над большим массивом данных. CPU в отличии от этой модели, использует другой подход. Вместо того, что бы использовать очень много маленьких процессоров, которые все делают, они строят достаточно увесистые ядра. Большие размеры кэша, обеспечивая достаточно высокую производительность при исполнении последовательного кода, но при этом очень трудно вместить большое количество ядер на кристалл. Допустим, сейчас Intel говорит о 4 — 8 ядрах на кристалле, в то время как у нас это море процессоров, массив процессоров исчисляется сотнями. Наш последний GPU например Tesla 10-ой серии — 240 процессоров, которые работают параллельно. Кардинальные отличия между архитектурами – то, что мы тратим площадь кристалла на сами вычислительные модули и делаем их очень много. В то время как центральный процессор, тратит площади кристалла, допустим, на кэш и достаточно небольшое количество относительно мощных вычислительных ядер. В соответствии с этим, программные модели тоже кардинально отличаются. Собственно поэтому мы и вынуждены были создать CUDA потому что традиционные языки программирования такие — как традиционный С не совсем подходят для выражения этого параллелизма. Нам пришлось взять стандартный С, расширить его мета-конструкциями для того, что бы программист мог выражать параллельные задачи и создать свой компилятор. В этом, наверное, и состоит главное отличие — масштаб параллелизма, к которому мы идем.
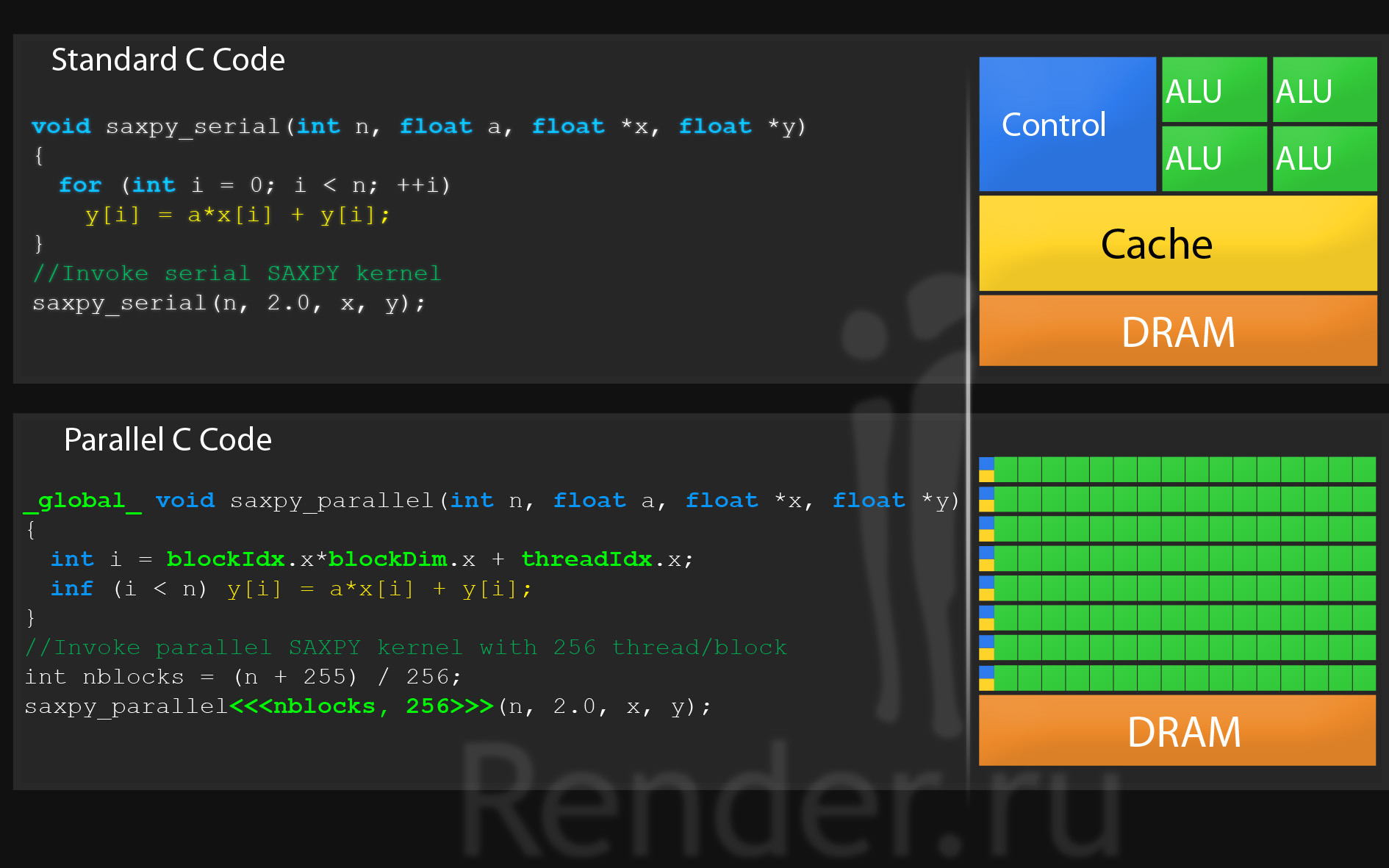
Пример кода на стандартном языке C, и пример кода с дополнениями для параллелизма.
Изначально CUDA как модель поддерживала гетерогенные вычисления — вы строите свою программу в виде секций. Есть секции, которые массивно параллельны — секции, которые будут исполняться на GPU. Есть секции, которые исполняются последовательно на CPU. С самой первой версии CUDA это было реализовано и поддерживалось. В одной программе вы могли смешивать параллельные и последовательные участки кода.
Дополнение. Параллелизм и новая архитектура NVIDIA Fermi
Помните поговорку - «Одна голова хорошо, а две лучше». Так вот, тут как раз можно, так и сказать. При этом, чем больше голов тем быстрее рождается идея и какой то продукт. На иллюстрации представлены как CPU, так и GPU. Как можно представить из ответа Юрия. GPU представляет собой массив из отдельных вычислительных ядер. При этом, кэш конечно присутствует, но не такой большой по сравнению с кэшем CPU.

Пример устройства CPU и отличие GPU. Как видно из иллюстрации в GPU используется намного больше ALU чем в CPU.
За счет увеличения количества вычислительных ядер (ALU) достигается производительность системы в расчетах.
На GTC 2009 была презентована новая архитектура — NVIDIA Fermi. О ней я и хочу поговорить в этом дополнении. Начнем с того, что теперь в новых чипах более 3х миллиардов транзисторов это конечно стало возможным благодаря переходу на 40 нм техпроцесс. Так же на долю вычислений предоставлено 512 так называемых CUDA ядер. На заметку в предыдущем чипе (G200) было 240 ядер, а в G80 их всего 128.

Архитектура Fermi. Теперь, как вы видите, используется достаточно емкий кэш 2-го уровня.
Теперь чип состоит из 16-ти потоковых мультипроцессоров, которые содержат по 32 шейдерных ядра. Что в совокупности и дает нам 512 CUDA ядер. Блоки расположены вокруг общей кэш-памяти второго уровня. Каждый из блоков состоит из планировщика и организатора, исполнительных модулей и файлов регистров и кэш-памяти первого уровня.
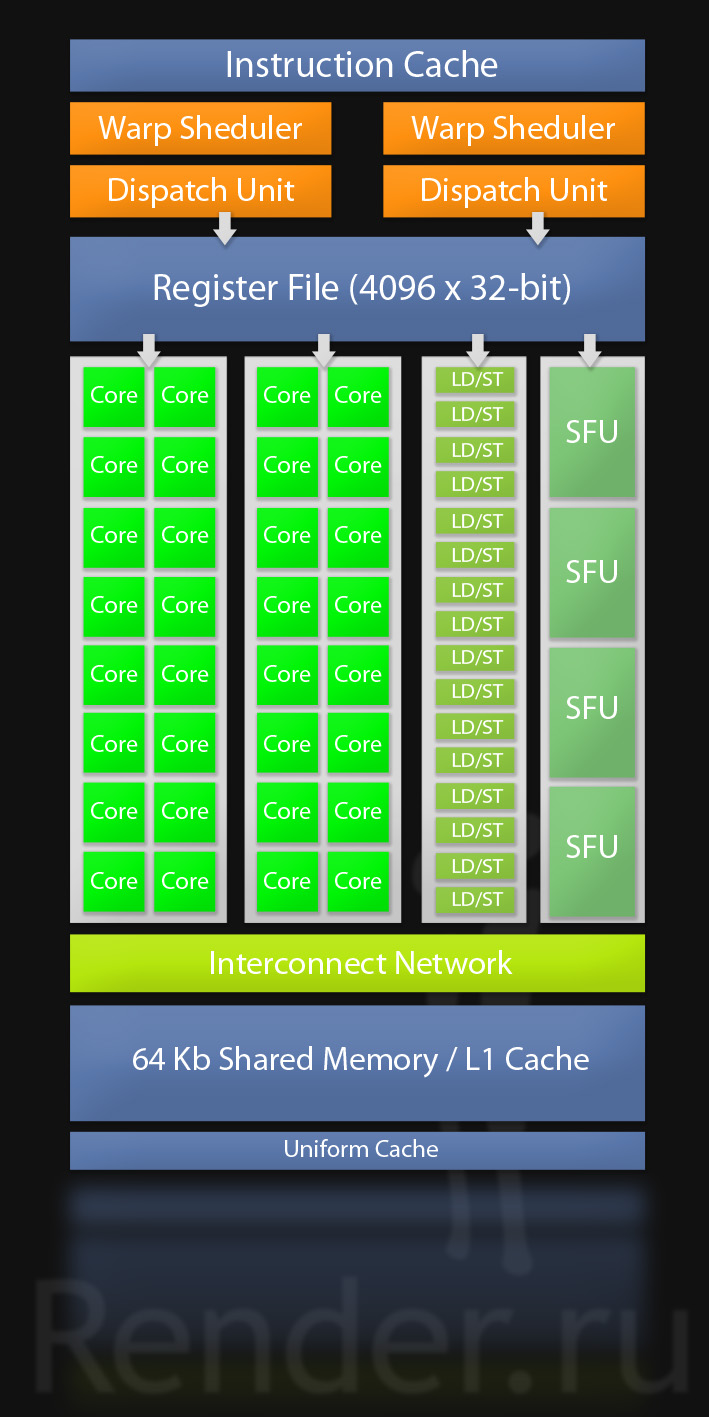
Детальная архитектура мультипроцессора.
Другое достаточно заманчивое решение, которое реализовано в Fermi – поддержка коррекции ошибок памяти (ЕСС). Что конечно скажется на производительности в лучшую сторону. А если учитывать то, что данная архитектура больше направлена и сориентирована на вычисления, то это позволит использовать продукты следующего поколения Tesla или Quadro в еще более сложных задачах и требующих продолжительных вычислений с большими объемами данных.
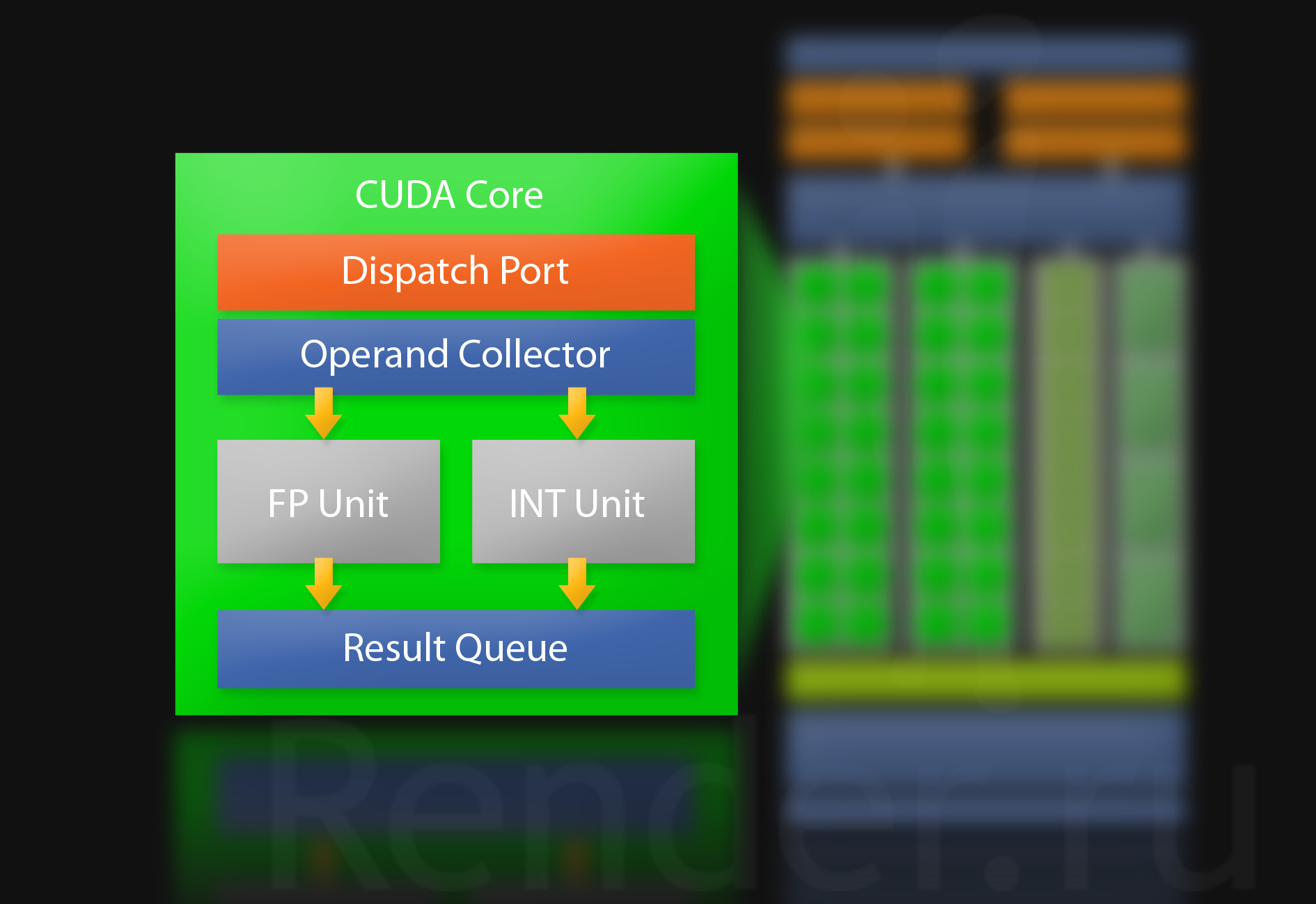
Одно из ядер мультипроцессора.
Так же следует отметить поддержку максимального объема памяти — 6 Гб, чип оснащается шестью 64-разрядными контроллерами памяти GDDR5, что дает 384-битную шину памяти. Для ускорения математических вычислений и выполнения других функций предназначена технология NVIDIA Parallel DataCache. В завершении скажу, что также Fermi поддерживает аппаратно такие средства программирования как C, C++, FORTRAN, и многие другие функции — такие как Open CL и Direct Compute.
GTC 2009 Презентация NVIDIA Fermi.
Вторая часть видео-версии интервью с Юрием Уральским.
Dimson3d | В демонстрационных материалах вы часто показываете, диаграмму производительности GPU по сравнению с CPU. Есть ли предел на данный момент производительности GPU? Центральные процессоры все равно упираются в определенный потолок.
Предел? (улыбаясь, переспросил Юрий) Хороший вопрос. Наверное, предел есть, просто мы живем в физическом мире. Вопрос можно поставить так: «Где этот предел находится?» - насколько этот потолок большой. Сейчас на самом деле пределом как я представляю, является так называемый power wall. Мы подходим к тому моменту, когда высокопроизводительным кластерам невозможно дальше наращивать производительность из-за того, что количество энергии, которое нужно для подпитывания машин слишком велико. В этом смысле как раз GPU, и вообще параллельные машины предлагают более эффективное решение. Один параметр, которым мы обычно хвастаемся — Performance per Watt. Это процент производительности на Ватт затраченной энергии или сколько GFlop потребляет энергии. Почему это так? Если вернемся к архитектуре возникает такая ситуация благодаря тому, что мы используем площадь кристалла на сами вычислители. Мы стараемся очень эффективно использовать доступную площадь и доступный бюджет при потребляемой энергии. Вместо того, чтобы кэшировать данные, наш механизм исполнения базируется на совсем других предположениях. Традиционные процессоры вынуждены строить большие массивные кэши и если программа использует набор данных, который не помещается в кэш, производительность процессоров сильно падает. Соответственно, чем выше мы хотим получить финальную производительность тем, больше нам нужно строить кэш, а кэш — структура достаточно не эффективная в плане потребляемой мощности и кэш сам по себе это не вычислительный модуль. Те транзисторы, которые вы тратите на кэш это просто занятая площадь, не выполняющая вычислений.

График производительности GPU по сравнению с CPU.
Dark | Как обстоят дела с коммуникационными расходами?
Совершенно верно, коммуникационные расходы — здесь ключевым моментом является то, что мы не строим большие массивные кэши, а используем площадь кристалла и энергетические ресурсы для добавления новых параллельных модулей — позволяет нам находиться на кривой роста производительности. Наращивать параллелизм, наращивать количество «маленьких вычислителей» значительно проще, чем увеличивать тактовую частоту. Центральные процессоры не могут позволить себе такой рост именно из-за того, что не могут наращивать параллелизм такими же темпами. Поскольку они вынуждены хорошо исполнять традиционные приложения — OS, прикладные программы (Word, Excel к примеру) и они просто не могут себе позволить уменьшить вычислительное ядро. Они не могут деградировать производительность всех этих приложений.
Dark | А есть ли какой то предел количеству процессоров, после которого производительность просто падает?
Наверно это зависит от способа использования технологий. Если у нас гипотетически приложение, которое использует максимально параллелизм, который не подразумевает ни какую коммуникацию между потоками исполнения, вы можете в принципе масштабироваться бесконечно. Проблемы накладных расходов возникают тогда, когда требуется, какое, то взаимодействие между параллельно-исполняющимися потоками. В связи с законом Даля, который говорит, что если у вас программа состоит из параллельных и последовательных участков кода, то максимальная масштабируемость производительности будет ограничена процентом времени, который вы проводите в последовательном участке когда. Если таких участков кода мало, то в принципе любая параллельная машина будет ускорять. И чем больше у вас процессоров работает параллельно, тем вы будете быстрее работать.
Dimson3d | В линейке вашей продукции для вычислений с помощью CUDA, представлены решения GPU GeForce, Quadro FX и Tesla. Все эти графические процессоры и системы могут использоваться для параллельных расчетов. Расскажите, пожалуйста, о NVIDIA Tesla — её основных отличиях, что позволяет её выделить среди других.
В первую очередь я скажу, что GeForce, Quadro и Tesla — просто названия продуктов. Это продукты, которые ориентированы на тот или иной рынок, все они используют одну и туже базовую архитектуру. Базовая архитектура, заложенная, в эти продукты поддерживает NVIDIA CUDA и в принципе используют одну и туже технологию. Скажем, различия начинаются на более высоком уровне, в плане того, что мы пытаемся ориентировать продукт на конкретный рынок. GeForce – продукты для Consumer направления — геймеров, использования в стандартных компьютерах. Quadro имеет ориентацию на более профессиональный рынок — визуализация, CAD, рабочие станции (workstations). Tesla – продукт, который ориентирован на вычисления в кластерах, если вы хотите построить кластер на основе GPU, то вы будете использовать Tesla. Если говорить о различиях между этими продуктами, то Tesla в частности отличается тем, что чипы проходят наиболее жесткое тестирование. Качество памяти, которая устанавливается на плату значительно выше, чем у GeForce. Поскольку мы сами выпускаем Tesla, мы даем гарантию, что она будет работать у вас 24 часа в сутки 7 дней в неделю. Это зависит от способа применения данного конкретного продукта. GeForce - скорей всего вы включите компьютер, сделаете все необходимое, поиграете и выключите его, и сможет ли он проработать целую неделю с постоянной нагрузкой 24/7? Если у вас сервер, вы проводите, какие то сложные научные расчеты, то вам важно, что бы он был доступен постоянно. Это продукты, которые ориентированы на разные способы применения.
Дополнение. NVIDIA Tesla краткое описание

Технические характеристики решений Tesla в desktop и server вариантах.
NVIDIA Tesla представлена в виде серверного решения и desktop варианта. Для разработчиков, и вообще для специалистов, кому не требуется большая производительность подойдет идеально подойдет desktop вариант, так же такое решение прекрасно подходит для создания персональных высокопроизводительных рабочих станций нацеленных на научные исследования и вычисления. Кстати, вот можно использовать такую комбинацию GPU Quadro или GeForce и NVIDIA Tesla. GPU выполняет визуализацию, а Tesla не обременяясь расчетами картинки выполняет только поставленные задачи по вычислениям. Плюс, их можно использовать совместно, непосредственно для вычислений.
С технической стороны данные решения выглядят так. Модель Tesla С1060 для настольных систем представлена в виде графического ускорителя, такого же, как у нас в системных блоках, но он не обладает портами для подключения мониторов. Внутри Tesla C1060 содержит чип T10 (GT200). У Tesla C1060 на борту 4 Gb GDDR3 графической памяти с интерфейсом в 512-bit. Потребление энергии данным устройством составляет 160W.
Но это решение для рабочих станций, где вы можете работать и выполнять расчеты непосредственно на рабочем месте. Но что делать, когда доходит дело до вычислений в огромных масштабах, в серверных залах с возможностью масштабирования? Для этого разработана NVIDIA Tesla S1070. Данное решение представлено в виде 1U корпуса, который устанавливается в стойку над или под сервером (см. иллюстрацию ниже). Данное решение представлено 4мя чипами T10 (GT200), каждому из них отведено по 4 Gb GDDR3 памяти, при этом в сумме получаем 16 Gb памяти. Но это решение к системам подключается через специальный HIC (host interface card) и кабель. В сами сервера x86 или рабочие станции в шину PCI-E x16 или x8.
Dimson3d | Мне как специалисту по визуализации, интересно, можно ли применить CUDA непосредственно в этой области. Возможна ли полная реализация системы визуализации? Хочется заметить, что многие пользователи жалуются - «Вот использовать эту мощность для визуализации финальных сцен, прикрутить к V-Ray или mental ray». Будет ли реализована новая система визуализации, которая будет полностью использовать потенциал графических ускорителей, или же можно будет перекладывать отдельные задачи, модули на GPU. Расчеты трассировки лучей или GI и т.п.
Да. Естественно мы считаем, что CUDA должна и может использоваться для финальной визуализации. К сожалению, пока о каких-то готовых продуктах, которые используют CUDA для визуализации говорить рано. Мы в этом направлении работаем можно отметить существование библиотеки NVRT демонстрация, которой была на SIGGRAPH 2007, она уже успешно применяется для визуализации. Многие компании из индустрии её используют. Но это незаконченный финальный продукт — именно библиотека, которая позволяет вам использовать CUDA GPU для решения задач трассировки лучей. Это базовый уровень. Предполагается, что на основе этой библиотеки вы будете строить свои приложения — визуализация с использованием Raytracing, или какие либо другие задачи. Это оптимизированная реализация трассировки лучей в общем смысле не обязательно для рендеринга и оптимизированная для наших процессоров GPU. Внутри компании, мы так же достаточно плотно занимаемся вопросами реализации, например альтернативных конвейеров рендеринга на GPU. У нас есть проект реализации Rays на CUDA. Так же проект из Microsoft Research где, они реализовали RenderMan с помощью CUDA и получили очень хорошее ускорение. Но пока это находится на стадии разработки и экспериментов.
Но все что мы видим интерес очень большой особенно в индустрии кино и телевидения. В частности студия PIXAR очень заинтересована в использовании CUDA в своих разработках и проектах. Просто пока еще рано говорить о каких то финальных продуктах, которые будут готовы для индустриального применения. В ближайшее время, учитывая то, что GPU становятся более доступными, а производительность растет не по дням, а по часам (улыбаясь, говорит Юрий). Я думаю в ближайшие несколько лет мы увидим, какие то готовые решения.
Еще можно наверное сказать относительно применения CUDA вообще в задачах для симуляции. Есть такой plug-in к 3ds Max — Ray Fire он не использует CUDA на прямую, а использует PhysX, а PhusX в свою очередь базируется на CUDA. Это как пример, как CUDA может помочь в решении задач не связанных на прямую с визуализацией.
Дополнение. OptiX, iray, RealityServer

Слайд с презентации NVIDIA на SIGGRAPH 2009 на котором представлена информация о интерактивном рейтрейсере — NVIDIA OptiX.
Вот мы и добрались до самого вкусного и интересного раздела дополнений. Хочется сразу вернуться на 1,5 года назад, когда я предрекал некоторым своим друзьям о скором будущем, когда Raytracing можно будет рассчитывать за минуты и причем в очень сложных сценах. Конечно, тогда все смеялись над таким заявлением. Но теперь смеяться не над чем. И так, OptiX — интерактивный визуализатор трассировки лучей, базирующийся на NVIDIA CUDA, и который может быть встроен в любой софт. Дело только за разработчиками. OptiX был представлен на SIGGRAPH 2009 на стенде NVIDIA.
На данный момент, OptiX на финальной стадии разработки, но то, что сделано уже сейчас впечатляет. Давайте посмотрим на то, что мы получаем и, что можно рассчитывать с помощью OptiX'a:
- Программируемые — поверхности, шейдеры, камеры;
- Не лимитированы только расчетом графики — лучи могут содержать любые пользовательские данные;
- Возможность масштабирования оборудования;
- Ambient Occlusion;
- Reflections;
- Refractions;
- Photon Mapping GI;

Ключевые особенности NVIDIA OptiX.
При этом, главное преимущество OptiX практически полная открытость для расширения и надстроек. Вы можете создавать свои собственные шейдеры, ИС, виртуальные камеры и многое другое. После чего, используя GPU NVIDIA Quadro FX создавать свои проекты с меньшими затратами времени на ожидание и исправления. Хотя пока на данный момент все это требует серьезной доработки в плане дружественности с пользователем, но в течение ближайшего года следует ожидать кардинальных изменений в нашем с вами программном обеспечении.
NVIDIA OptiX является частью AXE — Application Acceleration Engines, набор модулей для разработчиков в который помимо OptiX включены еще такие модули как SceniX и CompleX, но о них я расскажу в одной из следующих статей.

Слайд с презентации NVIDIA на SIGGRAPH 2009 на котором, представлена информация о новой системе визуализации mental images iray.
Наконец, для пользователей системы визуализации mental ray появилась возможность использовать все потенциалы GPU для визуализации самых сложных и насыщенных различными сложными поверхностями сцены. На SIGGRAPH 2009 был презентован новый продукт от mental images – iray. iray базируясь на архитектуре NVIDIA CUDA, позволяет использовать для визуализации все возможности GPU. iray является как компонента mental ray, так и RealityServer. Плюс ко всему, mental ray 3.8 с iray в течение ближайшего года будет интегрирован во все программы, создаваемые в OEM партнерстве с mental images. К примеру, следующие 3ds Max или Maya, а также SI, возможно будут обладать возможностью расчета финальной картинки с помощью mental ray и iray.
Если взглянуть на это с технической стороны, то модель данных решений выглядит следующим образом. Данные из приложения посылаются системе визуализации, в свое время программа проанализировав эти данные и настройки запускает визуализатор, а он, базируясь на архитектуре NVIDIA CUDA выполняет вычисления с помощью CPU и GPU.
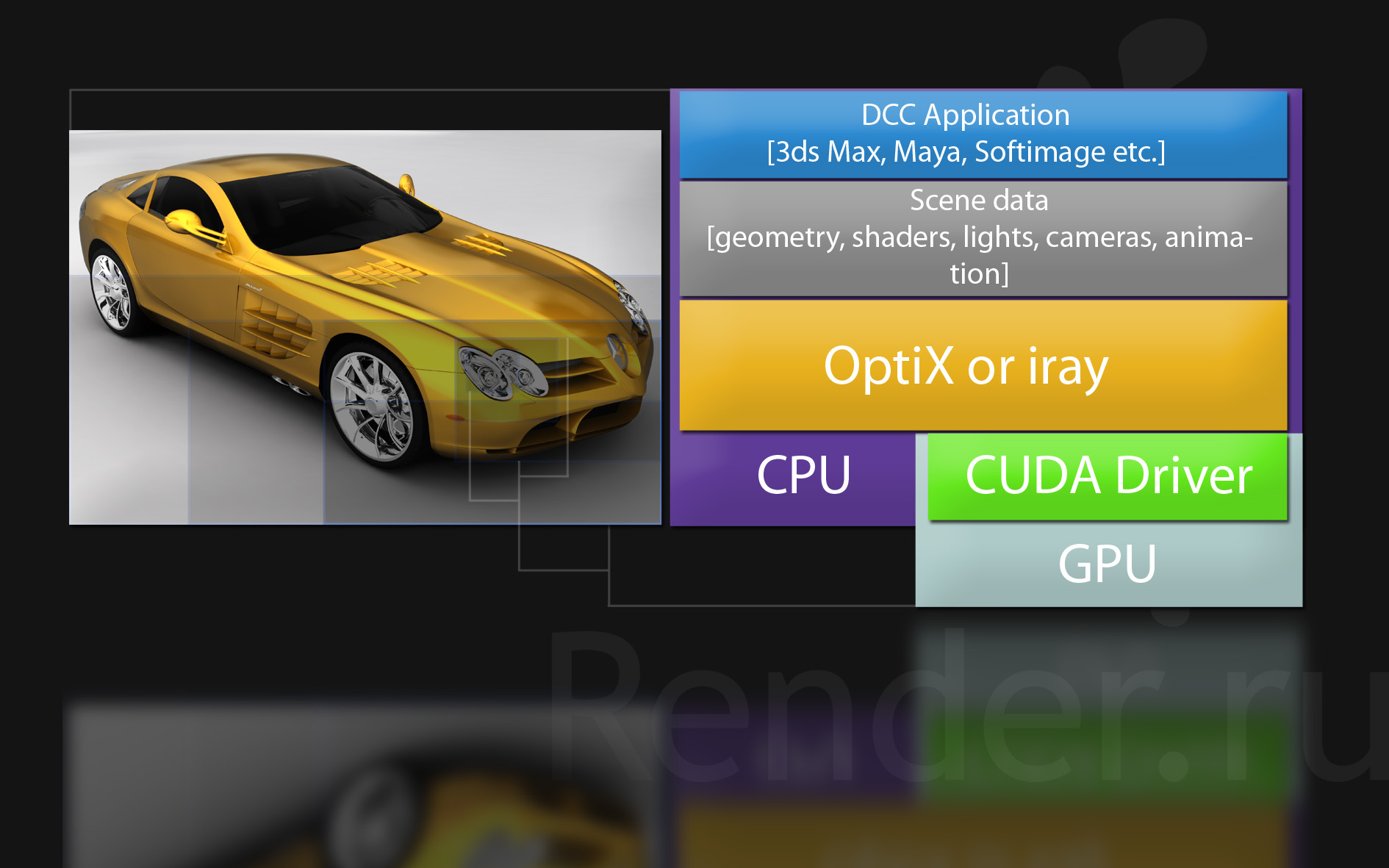
Схема использования GPU приложениями использующими код на CUDA. Для примера показана схема для OptiX или iray. Учтите что OptiX — интерактивная система, а iray это компонент mental ray 3.8 или RealityServer. Как интегрированные в DCC приложения, так и работающих независимо от них.
Вот как раз для расчетов на GPU применяется драйвер с поддержкой CUDA. Драйвер для работы с OptiX должен быть не ниже версии 190.38 (какой я использовал при написании этой статьи и подготовки демонстрационного материала). Данный драйвер уже поддерживает CUDA версии 2.3.
Но, а на какую графическую подсистему рассчитывается применение технологии OptiX и iray? Все как всегда сводится к вопросу о производительности и стабильности, и здесь как всегда ответ сам приходит на ум — Quadro FX и Tesla. Преимущество Tesla состоит в том, что она занимается исключительно расчетами — в таком случае можно использовать её как мощнейший сопроцессор. В случае с Quadro и Tesla мы получаем стабильность и гарантию того что все будет выполнено как задумано художником и не будет такого момента как перегоревшая в самый неподходящий момент GPU или сбои в работе оборудования. Хотя это можно и приписать к минусу — ведь далеко не все пользователи позволят себе покупку более дорогой Quadro и тем более Tesla. Однако подождем выхода конечных продуктов, непосредственно в приложениях для DCC и посмотрим, как будут реализованы эти технологии.
Ах, да совсем забыл сказать, что на данный момент для OptiX рекомендуется применение GPU NVIDIA Quadro FX 3800 и выше. Хотя я с достаточно большим успехом запустил демонстрационные примеры и на своей Quadro FX 1800. Все дело упирается в количество потоковых процессоров. У NVIDIA Quadro FX 1800 их 64, а у Quadro FX 3800 их уже 192 (как и у Quadro FX 4800\CX). И чем больше потоковых процессоров — тем лучше. Хм, раньше мы пытались под «кипение кристалла ЦП» заставить визуализироваться сложные сцены, теперь будем пытаться заставить «кипеть» кристалл графического ускорителя 8).
Это видео демонстрирует возможнсоти iray в RealityServer 2.4.
Но не одним iray мы едины. Учитывая, что есть и другие рендереры — V-Ray, Brazil и Final Render. У Chaosgroup (разработчик V-Ray) есть так же решение, разработанное с учетом того, что оно будет использовать GPU — V-Ray RT. Хотя в первом релизе на данный момент нет прямой поддержки GPU, и данное решение встраивается в 3ds Max в качестве Active Shade во Viewport. Однако хочется сказать, что разработчики уделяют этому огромную долю внимания — ведь получить визуализатор, который будет использваоть GPU для увеличения скорости рендера. Это очень большой шаг вперед. Но стоит другой вопрос — как быть, если у потенциального клиента и покупателя используются GPU не NVIDIA? Тут ведь нельзя просто взять и написать программный код, оптимизированный только под одну архитектуру и производителя. Есть отличный ответ — использовать Open CL (Open Computing Language). Данный язык не привязан к конкретной продукции — будь то NVIDIA или ATI. И разработчики в Chaosgroup как раз присматриваются именно к использованию Open CL, хотя в демонстрации, которую вы увидите ниже используется и NVIDIA CUDA.
GPU accelerated rendering of VRay part 1 - 20x speedup!
GPU accelerated rendering of VRay part 2 - 20x speedup!
Но вернемся к iray. Ниже даны примеры визуализации интерьера с помощью технологии iray. Достоверно я не могу сказать, сколько времени заняла визуализация этих изображений. Но на видео-демонстрации нового RealityServer 3.0 картинка визуализировалась неимоверно быстро — учитывая, что рассчитывались GI, Reflections. Refractions. Буквально несколько секунд, и готово.
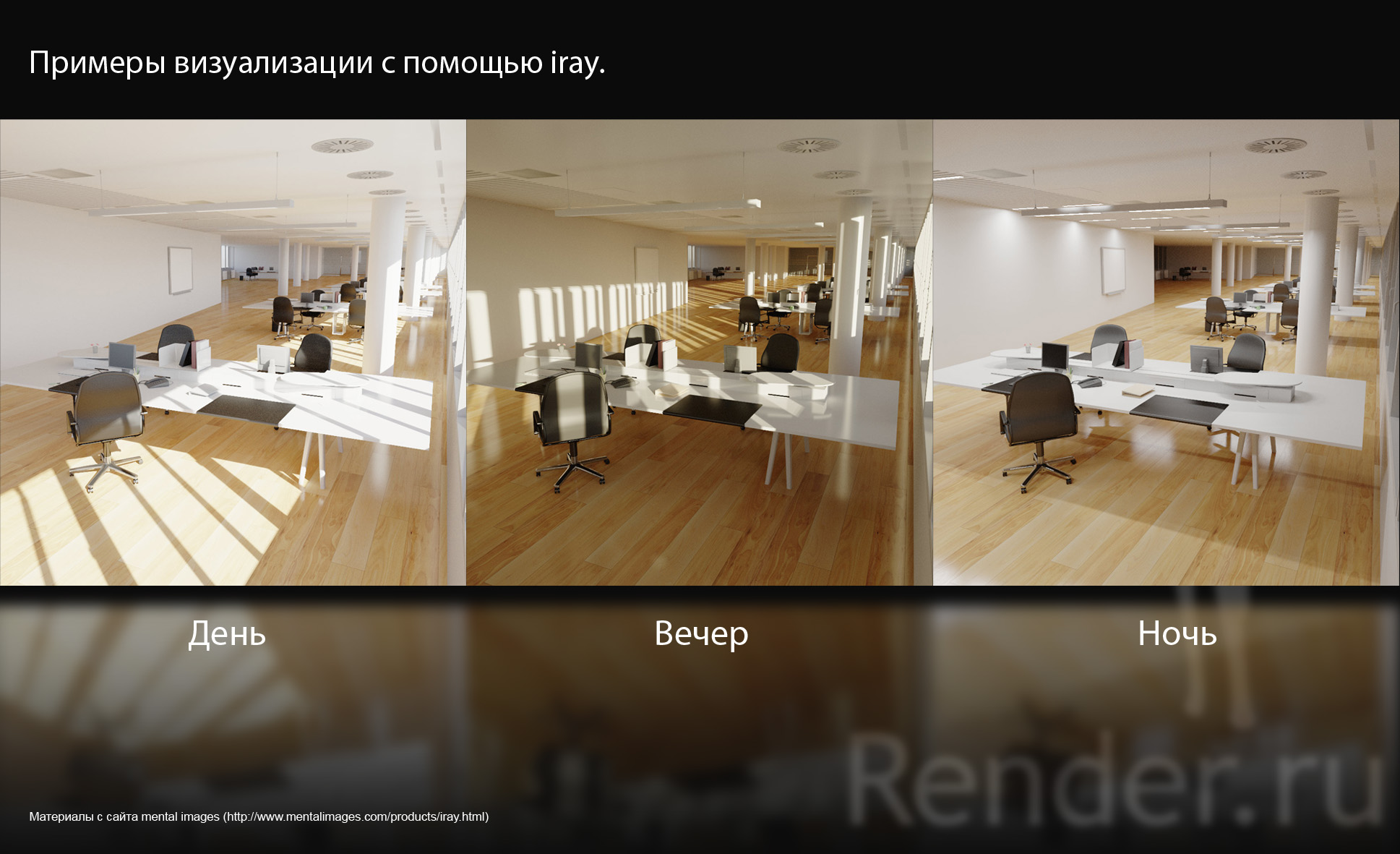
Пример визуализации интерьера офисного помещения с помощью iray.
Что хочется добавить в заключение и повториться в этом разделе дополнений. А вот что. Главное отличие iray от того же V-Ray RT и OptiX — в первую очередь он не является интерактивным средством визуализации. iray предназначается для увеличения скорости вычислений с помощью GPU и множества процессоров, которые находятся внутри графического чипа. Поэтому чем больше GPU будет у вас в системе и чем больше вычислительных ядер в каждом GPU (64 — 240 и выше), тем лучше. При этом если имеется такой продукт как NVIDIA Tesla, то мы получим высокопроизводительное решение для визуализации самых разнообразных сцен и моделей за достаточно короткие сроки.
Если применять RealityServer и новые решения Tesla RS, здесь появляется новый термин доселе не применявшийся в области визуализации - «облачные вычисления», об этом мы поговорим отдельно в статье посвященной iray и RealityServer. Весной 2010 года.
Видео презентации интерактивного Raytracing на модели Bugatti Verona.
Nvidia: Raytracing Bugatti Veyron
Это видео демонстрирует, как работает интерактивный трассировщик луча на примере модели Bugatti Veyron.